6. Kyo
6. Kyo – Gelbgurt
Es gibt keinen Misserfolg.
Entweder du hast Erfolg oder du lernst.
Kevin Kruse
Hier siehst du gerade den ersten und noch nicht vollständigen Aufschlag für den Gelbgurt. Wir freuen uns über Fehlerkorrekturen! Wenn du das Gefühl hast, hier etwas nicht nachzuvollziehen zu können, schreib uns bitte oder sprich uns beim CoderDojo an, damit wir das Script verbessern können. Wenn du es nicht verstehst, liegt es nicht an Dir und anderen wird es auch so gehen. Lass es uns gemeinsam für die nächsten Leser:innen besser machen.
Überblick
Herzlich Willkommen im Gelbgurt-Programm. Wir brauchen noch zwei Bausteine, bevor wir in die Bibliothek pygame kommen. Zunächst werden wir das Versionsverwaltungssystem Git kennen lernen. Und danach schauen wir noch kurz virtualenv an. Wie ganz am Anfang versprochen, werden wir uns dann daran machen, ein Weltraumspiel zu programmieren. Programmiertechnisch steht dabei im Vordergrund, das bereits erlernte zu festigen und zu vertiefen. Wirklich neu werden Arrays sein und der erste Kontakt mit Klassen. Zuletzt wollen wir einen ersten Blick auf html und css werfen und mit flask erste Webseiten an den Start bringen. Dabei lernst du gleich die ersten Grundlagen, wie eine Internetseite die du aufrust, auf Deinen Rechner kommst. Dafür lernen wir auch einiges über Linux kennen und warum dieses Betriebssystem für uns wichtig ist.
Git - Klappe die erste
Git gehört zu den sogenannten Versionsverwaltungssystemen. Diese lösen mehrere praktische Probleme. Stell Dir vor, du entwickelst ein etwas größeres Projekt. Dann kann es immer sein, dass du in eine falsche Richtung abbiegst und wieder Teile rückgängig machen willst. Oder du magst einen neuen Teil einfügen, der aber nur experimentell zur Verfügung stehen soll. Das Programm soll also in den Versionen stabil und testing genutzt werden. Hierbei helfen Dir Versionsverwaltungssysteme. Ihren größten Vorteil spielen sie aber aus, wenn du mit mehreren an einem Projekt arbeitest. Versionsverwaltungssysteme sind alt und es gibt viele verschiedene. Linus Thorvalds, der Erfinder des Linux-Kernels, war aber mit allen unzufrieden. Deshalb hat er eine neue Versionsverwaltung geschrieben - Git. Dieses ist inzwischen das am meisten genutzte System und wird von Plattformen wie github und gitlab verwendet. Vielleicht hast du von denen schon gehört. Für Git braucht es einen zentralen Server. Solche Plattformen können da sehr hilfreich sein, wenn man selbst keinen betreiben möchte. Um Github machen wir einen Bogen, da es von Microsoft gekauft wurde. Gitlab ist okay, aber auch ein Unternehmen und vieles von dem, was die haben, brauchen wir nicht. Wir könnten auch einen eigenen Server betreiben, haben uns aber entschieden, aktuell unsere Energie anderweitig zu investieren. Wir werden als Git-Server Codeberg verwenden. Das ist ein Verein, der nicht mit den Daten Geld verdient, sondern sich über Spenden finanziert. Bitte sprich mit Deinen Eltern darüber, ob es okay ist, dort einen Account anzulegen. Und klick Dir dann bitte bei codeberg.de einen Account.
Der Name „Git“ bedeutet in der britischen Umgangssprache so viel wie „Blödmann“.
Linus Torvalds erklärte seine Wahl des ungewöhnlichen Namens mit einem Witz sowie damit,
dass das Wort praktikabel und in der Softwarewelt noch weitgehend unbenutzt war:
“I’m an egotistical bastard, and I name all my projects after myself.
First ‘Linux’, now ‘Git’.”
„Ich bin ein egoistischer Mistkerl, und ich benenne all meine Projekte nach mir.
Zuerst ‚Linux‘, jetzt eben ‚Git‘.“
Linus Torvalds
Quelle: Wikipedia
Git ist sehr mächtig. Deshalb wollen wir uns dem ganzen langsam nähern und im Gelbgurt zunächst nur die elementaren Befehle lernen. Im Orange-Gurt lernst du, was man wissen muss, um ein Projekt zu managen.![]()
Wir beginnen mit einem neuen Projekt. Du loggst Dich bitte in Coderberg ein. Klicke dort auf das Pluszeichen neben Repository. Repository ist quasi ein Softwareprojekt. Gib dem ganzen einen Namen. Wir beginnen hier mit einem kleinen „helloWorld“, um gleich zu üben. Den Rest der Einstellungen lässt du jetzt erstmal so stehen und klickst unten auf „Repository erstellen“. Wunderbar. Dein erstes Repository ist erstellt. Codeberg gibt Dir jetzt eine kleine Anweisung wie es weitergeht. Lass den Tab offen, wir kommen darauf zurück. In PyCharm legst du bitte auch ein neues Projekt helloWorld an. Folgende Beschreibung gilt für Linux- und MacNutzende. Windows-Nutzer installieren sich entweder Git für Windows runter. Dort gibt es auch die Möglichkeit, Git auf der Kommandozeile zu nutzen. Oder du scrollst runter zum Kapitel Linux und kommst nach diesem Abschnitt hierin zurück. Für Git kann man auch grafische Oberflächen nutzen, aber tue Dir selber einen Gefallen und lerne gleich die Befehle. Nicht immmer hat man PyCharm zur Verfügung und machmal kann man mit den Befehlen auch mehr erreichen. Die grafische Anwendung macht nichts anderes, als genau die Befehle auszuführen, die ihr jetzt schreibt. Aber bei so einer Anwendung bist du immer davon abhängig, welche Optionen Dir die Anwendung zur Verfügung stellt. Dabei gibt es regelmäßig mehr, die du vielleicht dann und wann nutzen möchtest. Wenn Du die Befehle kannst, kannst du meist ohne Probleme die verschiedenen grafischen Oberflächen nutzen - umgekehrt klappt das dagegen nicht. Weiter geht's. Öffne bitte einen Terminal. Gehe in Dein Verzeichnis: Mit cd Pycharm gehst du in das Pycharm-Verzeichnis, mit cd helloWorld gehst du in Dein neues Projekt. Mit ls -lah kannst du Dir den Inhalt des Verzeichnisses anzeigen lassen. Da ist noch nichts drin. Jetzt „arbeitest“ du die Coderberg-Anleitung ab (ersetze <dein Benutzername> mit deinem Benutzernamen):
touch README.md
git init
git checkout -b main
git add README.md
git commit -m "erster commit"
git remote add origin https://codeberg.org/<dein Benutzername>/helloWorld.git
git push -u origin main
Diese Befehlsfolge brauchst du nur beim Anlegen eines neuen Projekts. Also keine Sorge, dass ist nichts, was jeden Tag vorkommt und was man auswendig kann.
Lass Dein Terminalfenster offen. Das brauchen wir gleich nochmal.
Wir wollen Dir jetzt die einzelnen Schritte erläutern, die du gerade vollzogen hast. Falls du das Gefühl hast, hier nicht bei jedem Schritt mitzukommen - bitte nicht entmutigen lassen. Vieles wird sich mit der Zeit klären. Wir würden Dich aber ungern völlig unkommentiert Zeilen abschreiben lassen. Du sollst immer nachzuvollziehen können, was du da gerade veranstaltest.
Mit touch legst du einfach eine leere Datei an, in diesem Fall heißt die README.md. Das am Ende md steht, verrät Dir, dass es sich um eine sogenannte Markdown-Datei handelt. Das lernst du auch bald. Es ist eine simple Art, Texte zu schreiben und wird viel verwendet. Diese Seite ist beispielsweise komplett in Markdown entworfen worden. git init legt ein git-Repository in diesem Verzeichnis an. Im Hintergrund werden da ein paar Dateien erzeugt, die Git braucht, um funktionieren zu können. Dazu zählt ein Verzeichnis, dass .git heißt. Der Punkt vor dem Verzeichnisnamen sorgt dafür, dass es bei Linux und Mac um ein verstecktes Verzeichnis handelt, also nicht immer zu sehen ist. Dann kommt git checkout. Git verwendet sogenannte Branches. Diese ermöglichen Dir, beim gleichen Projekt wie eingangs erläutert eine stabile Version und eine Version in Entwicklung nebeneinander laufen zu lassen. Mit git checkout -b main wird sichergestellt, dass du Dich im sogenannten Hauptzweig befindest. git add README.md bereitet die Datei README.md vor, um sie beim nächsten Push (kommt gleich) Deinem Projekt hinzuzufügen. git commit sagt git, dass das, was du gerade über git add hinzugefügt hast, mit einem Kommentar versehen werden soll. Das kann wirklich wichtig werden, damit man sich nachher noch daran erinnert, was man sich dabei gedacht hat ohne erst mühevoll aus den Codezeilen die Unterschiede herauszubekommen und zu raten, was sich der- oder diejenige beim Einchecken dieser Datei gedacht hat. Der Zusatz -m "Hier muss Dein Kommentar hin" fügt den Kommentar dazu. Macht man das nicht, fragt git nach dem Befehl nach dem Kommentar. Die Zeile git remote add verbindet das Repository auf Codeberg mit Deinem lokalen Repository. Und zu guter letzt schiebst du noch mit git push das was du über git add hinzugefügt hast - hier die README.md - hoch in Dein Repository auf Codeberg. Der Zusatz -u origin main sichert ab, dass lokal und remote den richtigen Zweig lokal und remote verwenden. Am Ende brauchst du Deine Zugangsdaten von Codeberg.
Okay, das war jetzt erstmal ziehmlich viel Zeug. du wirst sehen, im laufenden Betrieb gestaltet sich git (meist) deutlich einfacher. Also schauen wir uns mal das „Tagesgeschäft“ an. Geh in PyCharm und öffne mit File und dann Open das Verzeichnis HelloWorld. Jetzt machst du einen Rechtsklick auf das Verzeichnis. Dort wird Dir New und Python File angeboten. Da gibst du helloWorld ein. helloWorld.pas ging auch, aber PyCharm ergänzt das .py sonst von selbst. Er wird Dich dann fragen, ob er die Datei der Git-Überwachung hinzufügen soll. PyCharm kann bei Git Dir einige Arbeit abnehmen. Du kannst da jetzt ruhig zustimmen. Aber damit du lernst, wie das ohne solche Hilfen geht, machen wir das zunächst alles zu Fuß. Erst Laufen lernen, dann Fahrrad fahren. :) Okay, wie ein Hello-World zu schreiben ist, weißt du. Schreib ein einfaches Hello-World. Vielleicht bindest du noch eine hübsche Schleife drum. Dann gehst du in Deinen Terminal zurück. Mit git add helloWorld.pas fügst du die Datei hinzu. Mit git commit -m "denk Dir einen passenden Kommenar aus" committest du die Datei. Und jetzt sorgt ein git push dafür, dass die Datei zu Deinem Repository bei Codeberg übertragen wird. Gib Deine Zugangsdaten ein und dann wird die Datei schon gepusht. Du willst wissen, ob es geklappt hat? Dann geh auf die Codeberg-Seite. Klick oben auf Hello World und tata - da sollte die helloWorld.py zu sehen sein. Wenn nicht, schau, ob Dir die Meldungen weiterhelfen. Ist das auch nicht der Fall - lass uns an einem Donnerstag beim CoderDojo gemeinsam drauf schauen.
So richtig berauschend war das jetzt noch nicht. Okay, dann ändere mal Deinen Code ein wenig, also füge eine zweite Print-Zeile hinzu oder so. Dann kommt wieder das Trio: git add helloWorld.py, git commit -m "Dein Kommentar" und git push. Jetzt geht wieder auf die Seite von Codeberg, aktualisiere die Seite. Du siehst, das neben dem Dateinamen Dein letzter Kommentar steht. Klick jetzt mal auf den Dateinamen, also helloWorld.py. Dann auf Verlauf (rechts). Jetzt siehst du, welche commits es schon gab. Klick mal auf Deinen letzten. Jetzt siehst du, welche Zeilen sich geändert haben. Das kann echt eine Menge wert sein.
Soweit soll es uns mit git erstmal genügen. Du selbst kann bei regelmäßigen Commits sehen, was du geändert hast. Und vor allem kannst du leichter den anderen zeigen, was du gemacht hast. Gleich lernen wir noch, wie man sicherstellt, dass git Dinge nicht ins Repository schiebt. Wenn wir das nächste mal näher auf git zurückkommen, siehst du, wie Zusammenarbeit mit git ausschaut.
virtualenv
Wir wollen für das Spiel gleich ein neues Repository anlegen. Also mach bitte ein neues Verzeichnis wie Arcarde. Und lege ein entsprechendes Repository bei Codeberg an. Jetzt initialisierst du git und verknotest es mit Codeberg. Das kennst du alles schon vom vorherigen Kapiel. Um pygame nutzen zu können, müssen wir eine Bibliothek installieren, die standardmäßig nicht installiert wird. Das könnten wir jetzt auf dem gesamten System tun. Das ist aber aus verschiedenen Gründen nicht gut, alleine schon, weil du Dir so mit der Zeit Deinen Rechner vollmüllst. Wir schaffen für unserd Projekte ab jetzt immer eine Umgebung, in der die benötigten Pakete vom Rest des Systems abgeschottet werden. Am Anfang scheint das lästig, aber sei Dir sicher, du wirst es zu schätzen wissen. Du brauchst jetzt virtualenv. Das Terminalfenster hast du noch offen. Gib mal virtualenv ein. Kommen da irgendwelche Fehler oder kommt die Hilfeseite? Falls die Hilfeseite kommt, prima. Dann ist das schon installiert. Falls Fehler kommen - bei allen Betriebssystemen solltest du mit pip install virtualenv das ganze installiert bekommen. Wie bei anderem Installtionen - sowas kann sich schnell garstig darstellen. Bekommst du es nicht selber hin, sei bitte nicht entmutigt, sondern lass Dir helfen.
Für die Erstellung einer virtuellen Umgebung musst du nur in dem entsprechenden Verzeichnis sein und mit virtualenv -p python3 venv eingeben. Virtualenv (für virtuell environment, also virtuelle Umgebung) bekommt mit -p gesagt, welche Python-Version es verwenden soll. Und mit venv, in welchem Verzeichnis er die Dateien für die Umgebung ablegen soll. Das könnte auch anders heißen, aber bei venv dürften die meisten Programmiererinnen wissen, was sich dahinter verbirgt. Wenn du das gemacht hast, musst du es noch aktivieren: in Linux / Mac mit source venv/bin/activate. Unter Windows mit venv\Scripts\activate.bat oder mit venv\Scripts\Activate.ps1. In Deinem Terminal sollte jetzt (venv) stehn, wenn es geklappt hat. Wunderbar. Sonst ist das ein guter Punkt für den Donnerstag Abend...
Jetzt kannst du sorgenlos(er) Pakete bzw. Bibliotheken installieren. Das wollen wir mit pip install pygame gleich mal machen. Wenn das bei Windows-Nutzenden nicht läuft, probiert bitte py -m pip install -U pygame --user aus. Läuft das sauber durch? Der schnelle Test ist, dass du schnell python startest und ein import pygame eingibst. Wenn keine Fehlermeldung kommt, ist alles prima. Sonst - du weißt schon. Donnerstag und so.
Das Verzeichnis venv enthält nichts, was mit unserem Code zu tun hat. Deshalb wollen wir das auf keinen Fall in unser Repository hochladen. Das wäre echter Datenmüll. Lege eine Datei .gitignore an. Das kannst du über PyCharme machen. Rechter Mausklick auf das Projekt, New, dann New Scratch File und dann kannst du schon .gitignore auswählen. Da trägst du jetzt venv/. Jetzt wird git dieses Verzeichnis zukünftig ausschließen. Über diese Datei können ebenso einzelne Dateien ausgeschlossen werden. Du kannst ja schon mal in einer neuen Zeile \*.png eintragen, damit die Grafikdateien nicht alle bei Codeberg landen.
Nachdem du das erfolgreich zu Fuß gemacht hast, PyCharm kann das beim Anlegen eines neuen Projektes mit erledigen. Nun wirst du auch auf Umgebungen treffen, bei denen PyCharm nicht läuft (beispielsweise auf einem Webserver). Deswegen solltest du das auch über die Konsole können. Wenn du lokal entwickelst - wenn du bei PyCharme auf File und dann New Project gehst, gibt es den Puntk New environment using. Da kannst du virtualenv auswählen. PyCharm installiert das und aktiviert es. Wenn du unten in der Zeile nach dem Erstellen auf Terminal klickst, erhälst du dort eine Konsole mit aktivierter virtueller Umgebung. Und dort kannst du mit pip install pygame die Bibliothek ebenfalls installieren. Und schau mal oben in die Menüleiste - da wirst du auf Git zum Klicken finden. Es lohnt sich, beide Wege zu können. Deine IDE (also hier PyCharme) zu beherrschen, aber davon nicht abhängig zu sein.
Kultur I.
Wir kommen noch zu Linux, aber um Dir einen Vorgeschmack zu geben, besorge Dir mal seine Biographie „Just for Fun“ von Linus Torvalds und David Diamond. Das Buch gibt es auf Deutsch und auf Englisch. Das ist nicht neu, aber lohnt sich immer noch. Berliner:innen können sich das leihen.
Geh auf VOEBB. Da liegt es im Magazin der Amerikanischen Gedenkbibliothek. Kennst du nicht? Dann ist das eine gute Gelegenheit, Deutschlands größte öffentliche Bibliothek kennen zu lernen. Wenn du noch keinen Ausweis hast - den kannst du Dir in jeder Stadtteilbibliothek ausstellen lassen. Aus historischen Gründen ist Berlins Zentrale Landesbibliothek (ZLB) in zwei Gebäude aufgeteilt: am Halleschen Tor ist die Amerikanische Gedenkbibliothek (AGB) und die Kinder- und Jugendbibliothek Hallesche Komet. In der AGB bekommst du ein gigantisches Film- und Musikarchiv, Literatur, Kunst, Philosophie und andere Geisteswissenschaften. Die Berliner Stadtbibliothek befindet sich in der Breite Straße, Nähe Alexanderplatz. Da gibt es Informatik, Medizin, Wirtschaft, Jura, Naturwissenschaften. Bei öffentlichen Bibliotheken liegen die meisten Medien im Gegensatz zu wissenschaftlichen Bibliotheken in den Regalen. In der ZLB ist kein Platz, deshalb sind etwa 2/3 der Medien im Magazin. Es lohnt sich also immer, im OPAC (dem Bibliothekskatalog) nachzuschauen. Von den Magazinen gibt es gibt es gleich zwei Typen - die in den Häusern und die Außenmagazine. Bei beiden musst du die Bücher vorbestellen. Das kostet nichts, wenn du Dir die Bücher in die besitzende Bibliothek liefern lässt. Keine Sorge, falls Kosten entstehen würden, wird immer vorher gewarnt. Der Unterschied bei den Magazin-Typen ist, dass beim Inhouse-Magazin das Medien taggleich, spätestens am Folgetag Dir zur Verfügung gestellt werden sollte. Beim Außenmagazin dauert das ein paar Tage. Du kriegst eine E-Mail, wenn Dein Buch angekommen ist. Wenn du über VOEBB mal „Just for Fun Torvalds“ eingibst, wirst du schnell auf das entsprechende Buch treffen. Falls du nicht aus Berlin kommst, schau Dich mal um, was so die Bibliotheken bei Dir in der Umgebung zu bieten haben. Da wartet manche Überraschung. Falls du das Buch nicht leihen magst, das kriegt man für einen schmalen Taler bei den üblichen Verdächtigten Händlern im Netz. Also viel Spaß schon mal beim Lesen.
PyGames

Juhu, wir kommen zu pygames. Das ist eine Bibliothek, die es Dir ermöglicht, Grafik darzustellen und Tastatur- und Mauseingaben abzufangen, damit du sie gut verarbeiten kannst. Wenn du zockst, wollen wir gleich zugestehen, dass man mit pygames keine Hochleistungsspiele bauen kann. Aber du kannst damit schon eine Menge machen und vor allem viel Coding spielerisch lernen. Wenn du selber in der Dokumentation von pygame stöbern willst, findest du sie auf der pygame-Seite.
Wir brauchen jetzt erstmal einen Hintergrund für die Spielfläche und eine Figur. Bei OpenGameArt kannst du Dir was passendes raussuchen. Am besten gehst du auf Browse und dann auf Textures. Wichtig ist, dass du eine png-Datei nimmst. Eine Spielfigur kannst du bei Kenny runterladen. Das ist der Link für ein Spacespiel. Aber du kannst Dir natürlich auch eine andere Figur nehmen. Wichtig ist jetzt nur, dass diese beiden Dateien in Deinem Projektverzeichnis drin stehen. Die anderen Grafikdateien lass besser draußen. Auf geht es in den Code:
import pygame, os, sys
from pygame.locals import *
pygame.init()
fpsClock = pygame.time.Clock()
surface = pygame.display.set_mode((800, 600))
background = pygame.Color(100, 149, 237)
image = pygame.image.load(`canvas.png`)
meeple = pygame.image.load(`meeple1g.png`)
player_x = 100
player_y = 100
Stumpf Code abtippen ist nicht. Also was passiert hier. Wir holen uns erstmal Bibliotheken, neben pygame noch zwei, die uns ermöglichen, Dateien zu laden. Dann initialisieren wir pygame. Wir sagen der Bibliothek, dass es los geht. Dann brauchen wir einen Zeitgeber. Der spielt im kommenden Code noch eine wichtige Rolle. Mit display.set_mode legst du fest, wie groß das Spielfeld wird. Mit background legen wir eine Hintergrundfarbe fest. image lädt das Spielfeld und meeple die Figur. Mit player_x und player_y wird die Figur auf eine bestimmte Koordinate festgelegt. Die Grafikdateien müssen im gleichen Verzeichnis liegen wie diese Python-Datei. Und entweder tragen sie die Namen canvas.png oder du benennst den String dort so um, dass er auf Deinen Hintergrund zeigt. Das gleiche gilt für die Spielfigur. Die Bildschirmgröße spannt quasi ein Koordinatensystem mit 800-Punkten auf der x-Achse und 600 Punkten auf der y-Achse auf. Das kennst du aus der Schule. In der Schule ist der Nullpunkt aber links unten, hier ist er links oben. Wenn du in der Schule noch nicht mit Koordinatensystemen zu tun hattest: Stell Dir vor, dass es an Deiner oberen Bildschirmseite ein Lineal gibt mit 800 Strichen und seitlich ein Lineal mit 600 Strichen. Jetzt kannst du jeden Punkt auf dem Bildschirm genau bezeichnen. Erhälst du die Koordinaten (100,100) für die Spielfigur, gehst du in die obere linke Ecke und gehst 100 Striche nach rechts. Das ist die sogenannte x-Achse und steht bei so einer Koordinatenangabe immer vorne. Die zweite 100 gibt die sogenannte y-Achse an und sagt, wieviele Striche du auf dem Lineal nach unten gehen müsstest. Dann bist du auf der Koordninate (100,100) gelandet. Alles klar soweit?
Noch ein bißchen Code:
while True:
surface.fill(background)
surface.blit(image, (0,0))
pygame.display.update()
fpsClock.tick(30)
Die while-Schleife kennst du schonn. Die wird hier genutzt, um erstmal endlos das gleiche zu tun (denn es gibt ja nichts, was die Bedingung im Kopfteil von while auf False setzt). surface.fill setzt den Hintergrund mit dem, was du oben also background definiert hast. surface.blit sagt, wo der landen soll. Dieser Bildschirm muss regelmäßig aktualisiert werden, damit die Veränderungen von Spielfiguren angezeigt werden. Das macht display.update. Und die Zeile mit dem tick lässt kurz warten. Den Effekt, hier mit anderen Zahlen zu arbeiten probierst du bitte aus, wenn das Spiel schon ein wenig steht.
Jetzt haben wir festgestellt, dass die While-Schleife eine Endlos-Schleife ist. Das ist unpraktisch, weil wir aus dem Spiel auch noch rauskommen wollen. Nach der Zeile mit dem blit fügst du ein:
for event in pygame.event.get():
if event.type == QUIT:
pygame.quit()
sys.exit()
Probiere jetzt mal den Code aus. Nimm ruhig auch mal die While-Schleife raus bzw. kommentiere sie aus. Einfach, um zu sehen, was passiert. Da fehlt aber noch die Figur. Probiere die jetzt bitte selber in den Code einzubauen. Und nicht beim folgendne Code schauen, sondern es selber probieren. Und wenn du die positioniert hast, dann spiele mal mit den Koordinaten und versuche die Figur mal in die Mitte oder an einen Rand zu positionieren. Und zum Schluss ersetzt du Deine Koordinaten durch die Variablen, die du am Anfang definiert hast (player_x und player_y).
Das sollte dann ungefähr so ausschauen (natürlich mit jeweils Deinem Hintergrund und Deiner Spielfigur):
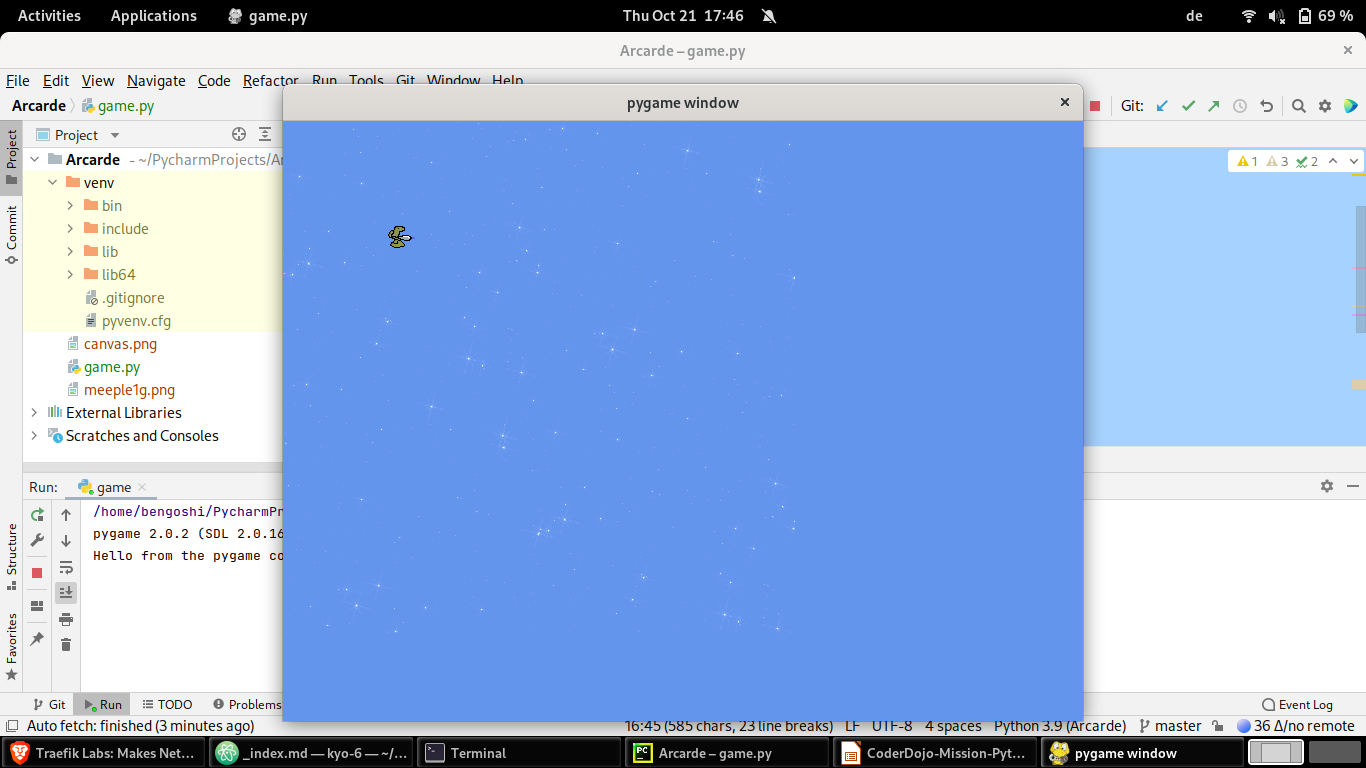
Insgesamt müsste bei Dir jetzt ungefähr dieser Code stehen:
import pygame, os, sys
from pygame.locals import *
pygame.init()
fpsClock = pygame.time.Clock()
surface = pygame.display.set_mode((800, 600))
background = pygame.Color(100, 149, 237)
image = pygame.image.load(`canvas.png`)
meeple = pygame.image.load(`meeple1g.png`)
player_x = 100
player_y = 100
while True:
surface.fill(background)
surface.blit(image, (0,0))
surface.blit(meeple, (player_x, player_y))
for event in pygame.event.get():
if event.type == QUIT:
pygame.quit()
sys.exit()
pygame.display.update()
fpsClock.tick(30)
Jetzt wäre es nicht gerade attraktiv, die Figur zu steuern, wenn wir jedesmal den Code anpassen. Also sollten wir die Tastatureingaben der Benutzerin abfangen und das Ergebnis direkt auf die Figur übertragen. Dafür brauchen wir ein weiteres Ereignis beziehungsweise Event. Wir legen also in die for-Schleife for event in pygame.event.get(): einen weiteren Teil dazu:
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_RIGHT:
...
Was passiert da? Mit jedem Durchlauf durch die While-Schleife (was ja fortwährend passiert) fragt pygame, ob es ein Event gibt. Falls das Event Keydown, also eine Taste gedrückt wird und wenn (sind ja zwei if-Bedingungen) auch noch Cursor-Taste gedrückt wurde, dann... ja was dann? Jetzt grübel mal bitte, was passieren muss, damit sich die Figur ein Stück runter bewegt. Das kannst du schon! Im Zweifel probiere ein bißchen rum. Du kommst bestimmt selbst auf die Lösung. Hängst du? Dann überlege, wie du die Koordinaten jeweils in die gewünschte Richtung um 100 verändern kannst; wobei 100 eine Zahl ist, bei der probieren musst, ob das für Dich passt. Wenn du das raus hast, dann versuche auch die anderen Richtungen zu programmieren. Auf K_RIGHT folgt K_LEFT, K_DOWN und K_UP. Wenn du das alles hast, teste es und schau, ob sich Deine Figur wie erwartet bewegt. Tip: Das Erhöhung oder Vermindern von Variablen braucht man irgendwie ständig. Deshalb gibt es hierfür eine Abkürzung. Du könntest schreiben player_x = player_x + 100. Aber du kannst das abkürzen mit player_x += 100. Nebenbei - das Erhöhen einer Variable nennt man inkrementieren, das Verringern dekrementieren. Dafür muss der Datentyp ein Integer sein. Grübel mal nach, warum ein Float dafür keine gute Idee wäre.
Der Code müsste dann ungefähr so bei Dir aussehen (nicht schmulen!, selber knobeln):
import pygame, os, sys
from pygame.locals import *
pygame.init()
fpsClock = pygame.time.Clock()
surface = pygame.display.set_mode((800, 600))
background = pygame.Color(100, 149, 237)
image = pygame.image.load(`canvas.png`)
meeple = pygame.image.load(`meeple1g.png`)
player_x = 100
player_y = 100
while True:
surface.fill(background)
surface.blit(image, (0,0))
surface.blit(meeple, (player_x, player_y))
for event in pygame.event.get():
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_RIGHT:
player_x += 100
if event.key == pygame.K_LEFT:
player_x -= 100
if event.key == pygame.K_DOWN:
player_y += 100
if event.key == pygame.K_UP:
player_y -= 100
if event.type == QUIT:
pygame.quit()
sys.exit()
pygame.display.update()
fpsClock.tick(30)
Hei, du hast den Grundstein für Dein Spiel gelegt! Jetzt ist Dir aber vielleicht schon aufgefallen, dass du mit der Figur in den „Abgrund“ stürzen kannst. Sie ist dann einfach weg. Die nächste Aufgabe ist, dass du genau das verhinderst. Versuche also den Code so zu erweitern, dass immer vor der Bewegung der Figur geprüft wird, ob diese Bewegung noch möglich beziehungsweise zulässig ist. Wenn nicht, wird die Bewegung ignoriert. Lass Dir ruhig einen Moment Zeit dafür. Das kriegst du bestimmt, aber es bedarf ein wenig Geduld. Wenn du diese Aufgabe gemeistert hast, dann überlege Dir, wie du diese Prüfung in eine Funktion auslagern kannst.
Du wirst eine Bedingunen schreiben müssen. Um diese zu vereinfachen, kannst du Bedingungen verknüpfen. Wenn du also beispielsweise sagen möchtest, dass der if-Teil nur dann wahr ist (und damit ausgeführt wird), wenn player_x = 100 und player_y = 100 ist, dann kannst du schreiben:
if player_x == 100 and player_y == 100:
print("Treffer!")
else:
print("Kein Treffer!")
Neben and ist or und not noch ganz wichtig. Für not zeigen wir Dir später noch Beispiele. Um die Vergleichsoperatoren bei Bedingungen vollständig zu machen:
== gleich
!= ungleich
> größer
< kleiner
> = größer oder gleich
<= kleiner oder gleich.
Jetzt bist Dd dran! Bevor du jetzt in die Tasten haust, sichere einmal Deinen Code mit git add game.py, git commit -m "Zwischenergebnis", git push. Nimm Dir Zeit, um das Spiel wie beschrieben weiterzuentwickeln. Und lass uns gemeinsam über Dein Ergebnis sprechen. Unten steht eine Möglichkeit, wie man es machen kann. Aber tue Dir selbst einen Gefallen und schau Dir das erst an, wenn du selbst zu einer Lösung gekommen bist. Wenn du wirklich nicht weiterkommst, hilft es Dir mehr, wenn du zeigst, wo du stecken geblieben bist, eine Richtung gesagt bekommst und weitertüftelst.
Der nachfolgende Code ist eine Möglichkeit, wie man es machen könnte.
import pygame, os, sys
from pygame.locals import *
pygame.init()
fpsClock = pygame.time.Clock()
surface_x = 800
surface_y = 600
surface = pygame.display.set_mode((surface_x, surface_y))
background = pygame.Color(100, 149, 237)
image = pygame.image.load('canvas.png')
meeple = pygame.image.load('meeple1g.png')
player_x = 100
player_y = 100
step_size = 50
def meeple_in(surface_x, surface_y, player_x, player_y, event_key):
if (event_key == pygame.K_RIGHT) and (player_x + step_size > surface_x):
return True
if (event_key == pygame.K_LEFT) and (player_x - step_size < 0):
return True
if (event_key == pygame.K_DOWN) and (player_y + step_size > surface_y):
return True
if (event_key == pygame.K_UP) and (player_y - step_size < 0):
return True
while True:
surface.fill(background)
surface.blit(image, (0,0))
surface.blit(meeple, (player_x, player_y))
for event in pygame.event.get():
if event.type == pygame.KEYDOWN:
event_key = event.key
if event.key == pygame.K_RIGHT or meeple_in(surface_x, surface_y, player_x, player_y, event_key):
player_x += step_size
if event.key == pygame.K_LEFT or meeple_in(surface_x, surface_y, player_x, player_y, event_key):
player_x -= step_size
if event.key == pygame.K_DOWN or meeple_in(surface_x, surface_y, player_x, player_y, event_key):
player_y += step_size
if event.key == pygame.K_UP or meeple_in(surface_x, surface_y, player_x, player_y, event_key):
player_y -= step_size
if event.type == QUIT:
pygame.quit()
sys.exit()
pygame.display.update()
fpsClock.tick(30)
Läuft so weit alles? Juhu! Da hast du wichtige Grundsteine gelegt. So alleine über den Bildschirm rennen fetzt aber jetzt nicht wirklich auf Dauer. erweitere bitte Dein Spiel um eine zweite Spielfigur und für eine zweite Spielerin. Diese nutzt statt der Cursor-Tasten die Tasten a für links, s für runter, d für rechts und w für rauf. Natürlich sollte diese Spielerin auch nicht vom Spielfeld fallen dürfen. Und du solltest Dir überlegen, ob du Code wiederverwendbar machst, in dem du ihn in Funktionen auslagerst.
Das ist vor allem Schreibarbeit. Nicht nur wegen Corona ist es nicht immer einfach, sich mit anderen zu treffen. Cool wäre doch, wenn wir jetzt die zweite Spielerin über das Netzwerk gesteuert werden könnte. Das machen wir als übernächstes. Vorher kommen noch zwei weitere Blöcke.
Kultur II.
Es wird Zeit für Kultur! Über eine Bibliothek, einen (legalen) Streamingdienst oder andere Wege besorge Dir doch mal den Film Hackers. Der ist zwar schon von 1995, aber immer noch sehenswert. Manche Filmszene wird dir immer wieder als Meme begegnen. Mal abgesehen davon, dass Du ein bisschen Computergeschichte dabei mitnimmst, zeigt es dir auch ein wenig den amerikanischen Blick auf den Begriff Hacker. Über den Begriff können wir ja gerne mal gemeinsam diskutieren. Wir orientieren uns dabei vielmehr an einem Satz, der Wau Holland zugeschrieben wird:
Ein Hacker ist jemand, der versucht einen Weg zu finden, wie man mit einer Kaffeemaschine Toast zubereiten kann.
Je nach, wie die Situation ist, können wir gerne versuchen, den auch mal gemeinsam zu schauen.
erste Begriffe für Netzwerktechnik
In dem Film Hackers geht es viel um Netzwerke. Auch wir wollen uns im nächsten Teil verbinden und dafür Netzwerke nutzen (und diese Seite rufst Du ja auch üebr ein Netzwerk auf). Deshalb wollen wir im ersten Schritt Begriffe (grob) erklären und klären. Wer schon tiefer in der Materie drin steckt - bitte berücksichtige, dass es hier um einen stark vereinfachten und ersten Aufschlag geht. Auch hier werden wir uns Stück für Stück in die (Un-) Tiefen dieses Themas nähern. Begriffe sind immer etwas abstrakt, aber sie helfen, hier einzutauchen. Wir stellen hier noch zeitnah eine Zeichnung ein, die am Ende des Kapitels stehen wird. Sie wird dir hoffentlich helfen, bei den ganzen Begriffen den Überblick zu behalten.
MAC-Adresse
Wenn du dich mit deinem Rechner mit einem anderen verbinden möchtest, geht es mit Deiner Netzwerkkarte los. Davon wirst Du vermutlich zwei haben - eine, um dich in ein kabelgebundenes Netz einzuklinken und deine WLAN-Karte. Letztere siehst du bestimmt nicht, weil sie eingebaut ist. Aber wenn du dich mit einem WLAN verbinden kannst, hast du eine :) Damit diese Karten von deinem Betriebssystem angesprochen werden können, brauchen sie eine eindeutige Adresse. Jede Karte besitzt deshalb eine sogeannte MAC-Adresse. Diese ist im Idealfall weltweit eindeutig. MAC-Adresse hat nichts mit dem Unternehmen mit dem angebissenen Apfel zu tun, sondern steht für Media-Access-Control-Address. Das sind sechs Blöcke mit hexadezimalen Zahlen. Falls Dir Hexadezimal nocht nichts sagt - an der Stelle nur: Da können die Zahlen 0 bis 9 und die Buchstaben A bis F vorkommen. Das schaut dann so 00-80-41-ae-fd-7e oder 00:80:41:ae:fd:7e aus. Bei Notebooks findest du manchmal auf der Unterseite einen Aufkleber, auf der die MAC-Adresse der Karten abgedruckt werden. Teilweise werden die MAC-Adressen genutzt, um insbesondere WLAN-Netzwerke abzuschotten. Hintergrund ist, dass du beim Anmelden an ein WLAN die MAC-Adresse deiner WLAN-Karte mitschickst. Wenn man dann im WLAN-Router einträgt, welche Netzwerkkarten sich überhaupt nur verbinden dürfen, kann das ungebeten Gäste fernhalten. Leider ist das kein wirklich wirksamer Schutz, da man auch frei gewählte MAC-Adressen mitschicken kann. Du wirst noch lernen, wie das geht - denn es kann gute Gründe geben, diese immer wieder ändern zu wollen.
IP-Adresse
Du wirst vermutlich zu Hause einen (WLAN-) Router haben, der dich mit dem Internet verbindet. Viele haben dafür eine Fritz-Box oder etwas anderes, was du oder deine Eltern von ihrem Internet-Anbieter gestellt bekommen haben. Das Gerät muss ja nun wissen, mit wem es im Netzwerk so quatscht, um seine Arbeit verrichten zu können. Stell dir das wie eine Straße vor, auf der viele Häuser stehen - die einzelnen Computer, Notebooks, Handys. Jedes Gerät hat eine Hausnummer, die IP-Adresse. Jetzt geizen wir aber nicht mit diesen Adressen, sondern vergeben für jeden Hauseingang (Netzwerkkarte) mit Namensschild (MAC-Adresse) eine eigene IP-Adresse. IP steht für Internet Protocol. Es gibt zwei Arten von IP-Adressen. Die älteren sind die sogenannten IPv4-Adressen. Die besteht aus vier Blöcken. Jeder Block kann eine Zahl von 0 bis 254 haben. Die kann beispielsweise so aussehen: 192.168.0.1. Das ist schön übersichtlich, hat aber den Nachteil, dass die Anzahl der möglichen Adressen doch recht begrenzt ist. Konkret stehen für das Internet circa 3,7 Milliarden Adressen zur Verfügung. Das hört sich erstmal fürchterlich viel an. Aber jeder Server im Netz braucht mindestens eine, jeder Internetanschluss, jeder Router... Auf jeden Fall sind die schon lange knapp, richtigerweise müsste man sagen, sie sind mehr als alle. Deshalb gibt es seit 1998 den Standard IPv6. Bis Ende 2020 sollen circa 50% des Internets darauf umgestellt worden sein. Du siehst, dass ist ein zäher Prozess. IPv6-Adressen bestehen aus acht hexadezimalen Blöcken. Das sieht dann beispielsweise so aus: 2001:0db8:0000:08d3:0000:8a2e:0070:7344. Führende Nullen in einem Block darf man weglassen und wenn ein Block ganz Null ist, darf das auch wegbleiben. Eine IPv6-Adresse könnte also auch so aussehen: 2001:db8::1428:57ab. Es gibt circa 340 Sextillionen (das sind 38 Nullen) an Adressen. Das sollte also erstmal reichen..
Unter einem Protokoll versteht man Regeln, wie Daten ausgetauscht werden. Um die Infos zwischen der MAC-Adresse und einer IPv4-Adresse klarzumachen, gibt es das ARP, also das Address Resolution Protocol, bei IPv6 wird dafür das NDP, also das Neighbor Discovery Protocol verwendet. Es genügt an dieser Stelle, dass du die Namen mal gehört hast und weißt, dass sie zwischen MAC-Adresse und IPv4 bzw. IPv6 stehen. So ein Protokoll kannst du dir wie eine Sprache vorstellen - in einer Sprache definieren wir auch, das dieses leckere Stück Obst ein Apfel ist. Da haben sich irgendwann irgendwie Menschen darauf geeinigt. Hätten sie damals sich auf Qufsdk geeinigt, würden wir Qufsdk dazu sagen und keiner könnte was mit Apfel anfangen. Eine solche Art von Einigung stellt ein Protokoll dar.
Port
Jetzt besteht so ein Haus ja nicht nur einem großen Saal, sondern meist aus mehreren Wohnungen. Wenn die Paketbotin jetzt drei Pakete hat, dann wäre es hilfreich, wenn sie die nicht einfach unten im Hausflur abwirft, sondern zur passenden Wohnung bringt. Umgekehrt warten die Bewohner schon gespannt auf die Pakete und lauschen schon, ob jemand an ihre Tür klopft. Hier sind wir bei den Ports angelandet. Jede IP-Adresse kann so verschiedene Dienste (Päckchen) entgegen nehmen und umgekehrt, können bestimmte Bewohner schon lauschen, ob man jemand klopft. Die Ports gehen bei 0 los und können bis 65.535 gehen. Die ersten 1024 Ports, sogenannte System-Ports oder well-known-Ports, haben eine bestimmte Bedeutung und werden vom Betriebssystem besonders abgesichert (da die Zählung bei 0 beginnt, ist der letzte Systemport also 1023). Der Port 80 ist beispielsweise immer für http da, also das, worüber du Internetseiten abrufst. Der Port 443 ist für https-Seiten, also abgesicherte Verbindungen. Du kannst das mal ausprobieren: Gibt in deinem Browser statt coderdojo.red coderdojo.red:443 ein. Damit sorgst du dafür, dass du die Seite coderdojo.red auf dem Port 443 aufrufst. Mit 80 wird das auch gehen, weil du automatisch auf den Port 443 umgleitet wirst. Wie sowas geht, lernst du auch bald. Wenn Du jetzt aber irgendeinen anderen Port angibst, dann kommt es zur Fehlermeldung. Der Paketbote klingelt dann nämlich bildlich gesprochen zwar im richtigen Haus, aber an der falschen Haustür. Andere bekannte Ports sind 21 für ftp, um Dateien zu übertragen, 22 für ssh, um auf fremde Rechner zugreifen zu können, 25 für SMTP, um E-Mails versenden zu können und u. a. 143 für IMAP um E-Mails empfangen zu können oder und 123 für NTP, um die Uhrzeit abrufen zu können. Für diese Ports gibt es Listen, die muss man also nicht wissen. Aber mit der Zeit, werden dir viele in Fleisch und Blut übergehen. Merken solltest du dir, dass die Ports unter 1024 für bestimmte Dienste reserviert sind und für andere Dienste nicht ohne weiteres zugänglich sind. Ports sind auch ein Teil eines Schutzkonzept von sogenannten Firewalls. Die machen nämlich gerne mal alle Ports zu und öffnen dann nur bestimmte, die wirklich benötigt werden. Da erschwert es Angreifern, unbemerkt in ein System reinzukommen oder aus einem System Daten rauszuschaffen (beispielsweise Bankdaten).
TCP
Jetzt tritt die Postbotim auf die Straße, um zum nächsten Haus zu fahren. Das Bild passt jetzt leider nicht mehr ganz, weil physikalisch laufen die Daten über ein Kabel, aber die Datenströme auf dem Kabel haben eine Ordnung, ein sogenanntes Protokoll, dass wir uns als Straße vorstellen. Dieses Protokoll nennt sich TCP (und die Kombination TCP/IP hast du vielleicht schon mal irgendwo gelesen). TCP steht für Transmission Control Protokoll, also Übertragungssteuerungsprotokoll. Das stammt von 1981 und ist ein echter Dinosaurier. Während die Dinos aber ausgestorben sind, ist TCP quicklebendig und wir alle tauschen täglich Daten über TCP aus. Eine Besonderheit von TCP ist, dass es zwei Punkte, die sogenannten Sockets miteinander verbindet. Es schickt nicht nur Daten zwischen diesen beiden Punkten hin und her, sondern schaut auch gleich, ob die richtigen Daten in der richtigen Reihenfolge (das ist alles andere als selbstverständlich) angekommen sind. Das ist super, der Nachteil ist jedoch, dass das aufwändiger ist und Zeit kostet. Das ist aber nicht immer praktisch. Stell dir vor, du schaust Netflix. Wenn da mal ein Paket verloren geht, das beim Prüfen festgestellt wird (Prüfvorgänge kosten immer Zeit), dann nochmal geschickt wird, wieder geprüft, in der Zeit kamen andere Pakete an, also muss alles erst sortiert werden... am Ende bleibt das Bild stehen, bis wieder alles seine rechte Ordnung hat. Du merkst, dass hier die gesicherte Datenübertragung vielleicht nicht ganz so wichtig ist. Der Gegenentwurf ist UDP (für User Datagram Protocol). Hier werden die Daten einfach nur rausgeblasen und die Gegenseite nimmt, was es kriegt. Läuft dann ein Datenpaket schief, gibt es unter Umständen ein kurzes Rauschen in einer Bildecke. Aber der Film läuft ungestört weiter. Bei einem Film ist das wichtiger, als dass das Bild immer perfekt übertragen wird. Wenn Du allerdings von einer Kasse die Daten überträgst, darf es auch mal länger dauern, wenn dafür alles richtig ankommt.
NAT
Wie bereits oben beschrieben, waren bei IPv4 die Adressen recht schnell alle. Also hat man sich etwas schlaues einfallen lassen: Deine Fritz-Box / Internet-Router bekommt nur eine IP-Adresse von deinem Interprovider. Die Geräte hinter deiner Fritz-Box erhalten auch eine Adresse, aber die sind in einem Adresskreis, der für solche Heimnetzwerke reserviert ist. Dadurch kann dein Rechner vielleicht die 192.168.192.4 haben und meiner auch - trotzdem weiß jedes Datenpaket, wo es hin muss. Denn wenn du eine Seite aufrust, schickt der Webserver die Seite zu der IP-Adresse deiner Routers zurück. Der Router hat sich gemerkt, wer bei der entsprechenden Seite etwas angefordert hat und kann es dann an die IP-Adresse deiner Rechners weiterleiten. Obwohl wir beide also in unseren Netzen 192.168.192.4 haben - im Internet ist von uns nur die öffentliche Adresse unseres Routers zu sehen - und die ist einmalig. Würdest du mich besuchen, dann müsste einer der beiden Rechner eine andere Adresse bekommen, da in einem Netzwerk jede IP-Adresse nur einmalig vergeben sein darf. Sonst kommt es zu sogennanten IP-Konflikten. Bei dieser Art von Konflikt hilft kein Reden, da muss einer die Adresse wechseln... Dieses Verfahren spart enorm viele Adressen ein und nennt sich Network Address Translation (NAT). Wenn Menschen von natten sprechen, dann meinen sie den Vorgang dieser Adressübersetzung. Soweit die Vorteile. Der Nachteil ist, dass es nicht ohne weiteres möglich ist, dass mein und dein Rechner miteinander quatschen können. Eine Lösungsmöglichkeit ist, dass man sich auf einen gemeinsamen Server einigt, über den man spricht. Wir sagen also der Brieftaube nicht, fliege mit der Nachricht zu Sarah, weil du zwar weißt, dass Sarah in der Tucholskystraße wohnt, aber die Hausnummer nicht kennst. Also sage ich meiner Taube - fliege zum Marktplatz. Sarahs Taube fliegt auch zum Marktplatz und holt sich den Brief dort ab und fliegt von da nach Hause - da sie von da kommt, weiß sie, wo sie hinfliegen muss. Fluch und Segen hängen eng beeinander - während der Weg über den Marktplatz umständlich wirkt, hat es aber den netten Nebeneffekt, dass keiner von dem anderen so genau weiß, wo er oder sie wohnt und ungebetene Gäste nicht so einfach vor der Tür stehen können.
TLS
Als das Internet geschaffen wurde, war der Kreis der Nutzenden klein, man kannte und vertraute sich. Die Zeiten sind schon lange vorbei. Deshalb fehlen aber in vielen ursprünglichen Konzepten, die wir bis heute nutzen, Kontepte, die den Schutz der eigenen Daten sicherstellt. Am Ende hat man über bestehende Protokolle weitere Protokolle drüber gelegt, die versuchen, Sicherheit zu schaffen. Eines davon ist der Transport Layer Security (TLS, Transportschichtsicherheit). Diese nimmt die Daten an einem Punkt, verschlüsselt sie und entschlüsselt sie am Endpunkt. Das S bei https (dargestellt durch das Schloss neben der Adressleiste im Browser) steht beispielsweise für TLS. Das ist super, verschlüsselt aber nur den Transportweg. Eine E-Mail wird so immer noch im Klartext auf dem Mailserver abgelegt. Jeder Administrator könnte sie lesen. Dagegen hilft nur die Ende-zu-Ende-Verschlüsselung. Da gehen wir nochmal darauf ein, wenn wir es mit einem praktischen Beispiel verknüpfen können.
Git - Klappe die zweiten
Gleich wollen wir anfangen, unsere App bereit machen, über ein Netz mit anderen Teilnehmenden zu kommunizieren. Jetzt solltest du aber mit Deinem aktuellen Code eine Version haben, die funktioniert und lokal läuft. Also bauen wir gerade eine neue Funktion ein. Es ist immer ganz nett, wenn man einmal den Stand von einem Stück Code hat, der läuft, dass man eine neue Funktion nicht direkt dort einbaut. Denn wenn es blöd läuft, zerschießt man sich durch rumprobieren die funktionierende Version. Jetzt könnte man den Code in eine neue Datei kopieren und in der Kopie arbeiten. Wenn du mit vielen Dateien arbeitest, wird das schnell unübersichtlich. Du kannst auch nicht mehr nachvollziehen, was du wo wie geändert hast. Und mir mehreren Menschen gemeinsam ist das auch kein gutes Verfahren. Hier kommt wieder git ins Spiel.
Man kann verschiedene Zweige seines Codes anlegen. Der Hauptzweig heißt üblicherweise „main“. Veraltet findest du auch noch die Bezeichnung „master“, der Begriff steht aber im Zusammenhang mit Master/Slave und sollte deshalb nicht mehr in solchen Zusammenhängen verwendet werden. Du könntest jetzt einen zweiten Zweig „testing“ schaffen oder - vielleicht hier passender - „network“. Wenn die Netzwerkanbindung dann mal läuft, kann die Funktion in den Hauptzweig integriert werden. Und bis dahin bleibt das Programm in „main“ unangetastet. Wir zeigen dir das mal in einem kleinen Beispiel wie das geht. Versuche das bitte erst einmal mit so einem einfachen Beispiel nachzuvollziehen, bevor du das dann mit deinem Spiel-Code machst.
Der einfachste Weg ist, bei codeberg ein neues Projekt anzulegen. Uns geht es jetzt nicht um Code, deshalb hatten wir es schlicht. Log dich ein und klicke auf das Pluszeichen neben Repositories. Der Maus-over sagt auch „Neues Repository“. Da gibst du einen Namen ein wie „helloWorld“ und scrollst bis an das Ende der Seite und klickst auf anlegen. Jetzt hast du die Möglichkeit, das Repository zu klonen, also lokal bei Dir abzulegen. Wir zeigen dir jetzt die Wege über PyCharm und über die Kommandozeile parallel. Wenn möglich, probierst du auch beide aus...
Zunächst die ersten Schritte auf Shell:
Du holst das Projekt auf deine Platt, indem du es klonst: git clone 'URL' . Du stellst sicher, dass du auf der branch „main“ bist mit dem Befehl: git branch -b main. Jetzt legst du mit einem einem Editor eine Datei an und haust da eine Zeile Code rein: nano helloWorld.py und schreibst da print("Hello World") rein. Abgespeichert wird mit Strg+X oder Control+X. Jetzt fügen wir die Datei hinzu und pushen sie gleich. Also kommt der bekannte Dreiklang: git add helloWorld.py, git comment -m "first commit" und git push. Jetzt legen wir die neue Branch mit git branch -b main an. Als nächstes verändern wir den Code und rufen die Datei erneut auf mit nano helloWorld.py. Binde um die Zeile Code eine Schleife drum, die den Print-Befehl zehnmal ausgibt. Jetzt kommt wieder der übliche Dreiklang: git add helloWorld.py, git comment -m "first loop" und git push.
Die gleiche Aktion in PyCharm:
Bei PyCharm schließt du dein aktuelles Projekt („File“ und „Close Project“). Jetzt hast du die Möglichkeit, ein neues Projekt anzulegen. Du wählst die Möglichkeit „Get from VCS“. In die URL kannst du die URL eintragen, die du von deinem neuen Projekt von Codeberg erhalten hast.
Leg eine neue Datei helloWorld.py an. Schreib print("Hello World") rein. Commite mit Strg+K und push darüber gleich. Dann gehst du über das Menü auf 'Git' und 'New Branch'. Ergänze den Code um eine Schleife, die das print zehnmal ausgibt. Commite und pushe wieder.
Und jetzt geht es zu Codeberg. Da findest du einmal:
Jetzt klickst du die Datei an. Hier ist der Code aus der main-Branch. Über Branch kannst du die test-branch auswählen und dir dort den Code anschauen.
Du erkennst also jetzt, dass du das Projekt mit zwei unterschiedlichen Codebasen fährst. Das ist cool! Und jetzt wollen wir noch die zwei Zweige zusammenführen.
Du wechselst jetzt wieder auf die main-Branch und wirst dort das Feld „Neuer Pull-Request“ angezeigt bekommen. Das klickst du jetzt an. Jetzt kannst du auswählen, welche Branch du mit welcher zusammenführen willst. In unserem Fall ist das Ziel main und du pullst von test-loop.
Jetzt siehst du, wie sich der Code unterscheidet und du kannst kontrollieren, was du machen willst. Was du dort siehst, ist eine sogenannte Diff-Ansicht. Die wird dir noch öfter begegnen. Wenn ein Minus dasteht, heißt das, die Zeile fällt weg und mit Plus-Zeichen kommt eine Zeile hinzu. Mit „Neuer Pull-Request“ führst du den Pull-Request aus. Dann ist der Branch test-loop leer und der Code ist im main-Branch gelandet. Voilà!
Diesen Pull-Request machst du natürlich erst, wenn du dir sicher bist, dass das neue Feature fehlerfrei läuft. In Teams kann man damit auch schön regeln, dass Code kontrolliert wird - du darfst zwar regelmäßig den Pull-Request anstoßen und dem Maintainer, also der Inhaberin eines Projekt sagen, dass du da was tolles im Angebot hast. Aber bestätigen dürfen ihn nur die Maintainer.
Wenn du das Thema „Pull-Request“ nochmal anders beschrieben lesen möchtest, schau doch mal hier.
MQTT
Jetzt wird es praktisch. Wir wollen ja unsere beiden Spielfiguren über das Netz verbinden. Wir nehmen dafür - tata - ein Protokoll. Jetzt hast du ja schon eine grobe Ahnung, was ein Protokoll ist. In diesem Fall verwenden wir MQTT, was für Message Queuing Telemetry Transport steht. Das stammt von 1999, ist also schon betagt. Es ist dafür geschaffen worden, damit Maschinen untereinander reden können. Durch IoT, also das Internet der Dinge, hat das Protokoll erheblich an Bedeutung gewonnen. Es ist super, damit beispielsweise etwas wie Sensoren Daten irgendwo hinsenden.
Hier wollt ihr mindestens zu zweit zocken. Aber da zwischen euch immer die Rechner hängen, reden am Ende doch die Maschinen.. MQTT hat reservierte Ports auf 1883 und 8883. Auch damit kannst du jetzt schon was anfangen. MQTT kann über TLS abgesichert werden. Den Fall wollen wir aber erstmal (noch) nicht betrachten. Eine Besonderheit bei MQTT ist, dass es nicht einfach Daten zwischen zwei Punkten austauscht. Wie gesagt, eigentlich ist das für IoT gedacht. Deshalb gibt es zu jeder Nachricht eine Überschrift, einen Topic. Das ganze ist dadurchz hierachisch aufgebaut. Stell Dir ein Fahrrad vor, dass Sensoren hat von Licht, Reifenluftdruck, Abstand zu Autos rechts und links und so. Dann würde der Reifenluftdruck für dein hinteres Rad gemeldet werden als Fahrrad/Rad/2/Luftdurck. Das Vorderrad hat dann Fahrrad/Rad/1/Luftdruck. Das mag erstmal komisch ausschauen, ist aber total praktisch. Im Spiel könnten wir dann nämlich sagen Arcarde/Spieler/Max/Standort, Arcade/Spieler/Max/Punkte oder Arcarde/Bots/12/Standort. Warum ist das praktisch? Wenn du dir von allen Spielern den Standort ausgeben lassen willst, schreibst du Arcarde/Spieler/*/Standort. Dann empfängst du nur ihre Standortdaten, nicht aber ihren aktuellen Punktestand. Wenn dich aber alle Daten interessieren, die Bot Nummer 12 präsentiert, schreibst du Arcarde/Bot/12/*. Du musst dir also überlegen, was für Daten sollen transportiert werden und wie können die vernünftig gegliedert werden. Einen Punkt wollen wir an dieser Stelle noch erklären, die anderen kommen dann im laufenden Projekt.
Was fehlt uns jetzt noch? Wir brauchen für die Spielenden eindeutige Bezeichnungen. Da könnten wir darauf vertrauen, dass die Spielerinnen schon immer andere abweichende Namen wählen. Oder einen Zufallsgenerator anwerfen. Aber für diesen Fall gibt es eine eigene Funktion - die UUID, was für Universally Unique Identifier steht. Dabei handelt es sich um eine 128-bit große Zahl, die zufällig generiert wird. Die Chance ist recht gering, dass zweimal die gleiche Zahl auftaucht und gleichzeitig haben alle das selbe Format. Das schaut dann ganz praktisch so aus:
import uuid
localPlayerId = f"player-{uuid.uuid4().hex}"
wie Du so Snippets (engl. Schipsel) eben mal kurz testen kannst, ohne gleich ein Programm dafür anlegen zu müssen? Klick in PyCharm auf Python Console und probier das oben mal aus. Ergänze noch ein print(localPlayerId) und du kannst gleich sehen, wie das ausschaut. Wenn du die Cursor-Taste hoch nimmst, kannst du auf die letzten Befehle zurückgreifen. So kannst du zum Testen schnell mal ein localPlayerId2 = f"player-{uuid.uuid4().hex} anlegen und ausgeben lassen, ohne alles nochmal schreiben zu müssen.
Für MQTT gibt es auch hier auch noch die Starthilfe:
import Examples.pyMqtt.mqttdatabus as mqttbus
mqttServer = "mqtt.eclipseprojects.io"
mqttTopicBase = "coderdojo/arcade"
mqb = mqttbus.MqttDataBusMessage(localPlayerId, mqttTopicBase, server=mqttServer)
mqb.startDataBus()
Eclipse ist eine gemeinnützige, belgische Organisation, die eine Plattform für die Entwicklung von Software. Am bekanntesten ist ihre gleichnamige IDE - also wie PyCharm-, die vor allem unter Java-Entwickler:innen beliebt ist. Eclipse stellt freundlicherweise einen MQTT-Server zur freien Verfügung. Gerne setzen wir später auch mal zusammen einen eigenen auf. Jetzt wollen wir erstmal unseren Fokus auf die Nutzung legen. Du siehst, dass eine Bibliothek für die Nutzung von MQTT importiert wird. Danach wird der Server und der Topic definiert. Das ganze bauen wir zusammen und stellen dann eine Verbindung her. Jetzt müssen wir noch die Koordinaten übertragen. Die x/y-Koordinaten deiner Figur kennst du. So sendest du sie:
mqttBus.sendData(
f"""{{
"x": {x},
"y": {y}
}}"""
)
Für deine Mitspielerin musst du jetzt erstmal mitkriegen, welche Spieler gerade dabei sind und wo sie sich befinden. Wir fassen zwar erstmal alle möglichen IDs ab, aber im ersten Schritt solltest du davon ausgehen, dass nur ein Mitspieler dabei ist. Wenn du eine coole Socke bist, kannst du natürlich im nächsten Schritt den Fall implementieren, dass sich mehr als zwei Spielerinnen treffen. So könntest Du rauskriegen, welche Spieler versammelt sind:
foo
Der Rest folgt bald...
ATTiny löten
Dieser Teil ist Bestandteil eines unserer Präsenz-Workshops. Wir werden die Inhalte dazu aber zeitnah online stellen.
Hier sind schon einmal die Folien des Workshops.
ATTiny Programmieren
In den Präsenz-Workshops geben wir dir am Ende des Lötteils zum Testen einen fertig programmierten ATTiny. Das ist aber wie fertiger Kartoffelbrei - macht satt, aber nicht glücklich. Wir wollen den also selber programmieren. Dafür bedarf es ein wenig Vorbereitung. Zum Coden installierst du dir am besten die AVR IDE. Wenn du da Unterstützung brauchst, stehen wir dir bei den Workshops oder donnerstags gerne zur Seite. Zum Testen des Codes schaffst du dir ein Konto auf Wokwi. Klar nimmst du dafür Fakedaten, oder?
Als nächstes brauchen wir einen Programmer. Das ist ein Stück Hardware, welches deinen Code nachher auf den ATTiny bringt. Das kannst du dir später auch gut zusammenlöten. Aber dann musst du für jede Codeänderung den ATTiny aus dem Sockel ziehen müsstest und wieder reinstecken, ist das erstmal unpraktisch. Auch wenn man vorsichtig ist, geht das nicht lange gut. Zum Rumspielen nimmst du dir besser ein Breadboard und steckst alles zusammen.
Als nächstes nimmst du dir sechs Headerkabel mit männlichen Steckern an beiden Enden, das sind diese kurzen Kabel zum Bauen von Schaltungen auf dem Breadboard. Die steckst du erstmal in den Programmer.
Dann nimmst du dir diese Zeichnung
und verbindest die Headerkabel passend mit dem Breadboard.
Stück
für
Stück.
Und dann nimmst du dir noch eine einfache LED und verbindest sie mit mit Port 1 und VCC. Der VCC entspricht dem Pluspol, der Port dem Minuspol. Bei der LED muss die Anode zum Pluspol zeigen und die Kathode (Merkhilfe: _K_athode / _k_urzes Bein) zum Minuspol.
Die LED ist für die Aufwärmübungen.
Bring den erstmal zum Blinken, bevor du dich am Stripe versuchst. Weil wir aber gerade am Basteln sind, machen wir das erst noch fertig. Isoliere den Stripe am Anfang ab. Sei vorsichtig - da kann man leicht bei abrutschen...
Dann verbindest du das ganze mit dem Konnektor.

Die Enden isolierst du ab. Aber bitte nicht mit so einem Messer. Dafür gibt es Abisolierzangen.
Und bei der Gelegenheit geht es gleich nochmal zum Lötkolben...
Die Enden verzinnst du jetzt. Das sollte dann ungefähr so aussehen:
Der Pluspol (rot) kommt auf VCC, der Minuspol (weiß) auf Ground und das Datenkabel (grün) auf Port 0.

Jetzt kommt der Programmer in deinen USB-Port und dann kann es mit dem Coden losgehen!
In einem Tab solltest du dir die ATTiny-Referenz aufrufen.
Dann die Hände entspannt auf die Tastatur legen und los geht's...
Wir fangen erstmal mit einem ganz einfachen Stück Code an.
#include <FastLED.h>
#define LED 1
void setup() {
pinMode(LED, OUTPUT);
}
void loop() {
digitalWrite(LED,HIGH);
delay(1000);
digitalWrite(LED,LOW);
delay(1000);
}
Wir kommen gleich zum ersten großen Unterschied zwischen C und Python: Bei Python läuft im Hintergrund ein Stück Software, was aus dem Script maschinenlesbaren Code produziert. Der Vorteil ist, dass du so etwas wie die Python-Shell nutzen kannst. Die Alternative sind sogenannte compilierte Sprachen. Da muss vor einer Anwendung der Code erst compiliert werden. Das Ergebnis ist eine direkt ausführbare Datei. Der Vorteil von so einer Script-Sprache wie Python (oder Ruby, Pearl und einigen anderen) ist, dass etwas wie eine Python-Shell möglich ist. Der Code ist direkt ausführbar, was das Entwickeln vereinfacht und beschleunigt. Der Nachteil ist, dass der Code erst zur Laufzeit für die Maschine lesbar gemacht wird und dadurch langsamer ist. Und ein Python-Interpreter muss immer im Hintergrund laufen. Für schmale Maschinen wie einem ATTiny ist das also nichts. C gehört zu den compilierten Sprachen. Der Code muss also immer erst compiliert werden und kann dann auf den Microcontroller gespielt werden. void zeigt an, dass eine Funktion nichts zurückliefert. Wir brauchen zwei Funktionen. Wie die Namen schon verraten, sorgt die erste für das Setup und die zweite bindet eine nette Schleife um den Code. Während bei Python Codeblöcke durch passende Einrückungen zusammen gehalten werden, wird das bei C - wie bei vielen anderen Sprachen - durch geschwungene Klammern definiert. Im Englischen heißen die übrigends curly brackets. Einrückungen sind zur besseren lesbarkeit zwar trotzdem üblich, aber sie sind syntaktisch nicht wichtig. Deswegen müssen Codezeilen mit einem Semikolon abgeschlossen werden. Jede Zeile bietet eine Chance, genau das zu vergessen. Wenn dein Code also mal nicht läuft, wäre das mit das erste, auf das ich an deiner Steller mal schauen würde.
Was passiert jetzt bei dem obigen Code? Die Zeilen, welche mit einer # beginnen, werden vom Compiler ausgewertet, bevor der Code übersetzt wird. include entspricht einem Import aus Python. Mit define wird der erste Ausdruck im Code gesucht und durch den zweiten ersetzt. Das hilft, Code lesbarer zu machen. Nimm dir den Code und hau den erstmal in das Wokwi rein. Da musst du an den ATTiny bei der Simulation noch eine LED und zwei Kabel ergänzen. Löten durch Klicken quasi. Kriegst du ihn da zu laufen? Super, dann pack ihn in die AVR-IDE rein. Klick erst den Haken an, um den Code zu überprüfen. Läuft alles durch? Dann klickst du auf Upload und wartest kurz. Im Zweifel musst du die LED mal ziehen. Blinkt sie? Super! Spiel mal ein bißchen damit, um damit warm zu werden. Lass das Teil schneller blinken, tausche mal den Port. Wenn du da soweit fit bist, geht es auf zum Stripe.
Hier wäre ein einfaches Beispiel dafür:
#include "FastLED.h"
#define NUM_PIXEL 16
#define DATAPIN 0
CRGB leds[NUM_PIXEL];
void setup() {
FastLED.addLeds<NEOPIXEL, DATAPIN>(leds, NUM_PIXEL);
}
void loop() {
static uint8_t hue = 0;
FastLED.showColor(CHSV(hue++, 255, 255));
delay(10);
}
Auch hier - fang bitte an, mit dem Code zu spielen. Nimm dir dafür das Wokwi und statt des Stripes nimmst du dir im Simulator einen NEOPIXEL Ring. Wenn dir hier irgendwo nicht klar ist, was der Code macht, zögere nicht, und frage bitte.
Die vorhandene Basis erweitern wir jetzt:
#include "FastLED.h"
#include <avr/power.h>
#define NUM_PIXEL 16
#define DATAPIN 0
CRGB leds[NUM_PIXEL];
void setup() {
clock_prescale_set(clock_div_1);
FastLED.addLeds<NEOPIXEL, DATAPIN>(leds, NUM_PIXEL);
}
void loop() {
static uint8_t offset = 0;
static uint8_t increment = 1;
FastLED.clear();
offset = offset + increment;
leds[offset % NUM_PIXEL] = CRGB::Green; ;
FastLED.show();
if(offset % NUM_PIXEL == 0) {
increment *= -1;
}
delay(20);
}
Auch hier - packe den Code ins Wokwi, baue dir den NEOPIXEL-Ring an und versuche den Code zu verstehen. Die erste Zeile im loop ist erklärungsbedürftig: In C müssen anders als in Python Variablen immer mit ihrem Typ definiert werden, bevor sie benutzt werden können. offset wird als Integer definiert und startet mit 0. static sorgt dafür, dass der Wert von offset beibehalten wird, wenn die Funktion verlassen wird und neu dorthin reingesprungen wird.
Wenn du da eingestiegen bist, versuche den Code dahin gehend abzuändern, dass die LEDs, immer wenn sie oben anschlagen, die Farbe wechseln. Hier wäre eine Musterlösung.
Geschafft - na, dann ist eine Regenbogen das nächste, was ansteht! Natürlich gilt wie immer beim Coden - selber probieren und erst wenn es läuft, auf die Musterlösung schauen. Wenn du hängst, frag lieber, ob wir dir einen Stupser geben können, bevor du auf die Lösung schmulst. :)
War es das schon mit dem Gelbgurt? Mitnichten! Aber wir erarbeiten gerade das Programm. Es lohnt sich immer wieder vorbeizukommen, da wir die Seite Stück für Stück ergänzen.